- The Challenge of Hyperscale Incident Management
- DrP’s Programmatic Automation at Scale
- Transformative Impact on MTTR and Engineering Efficiency
- A New Standard for Site Reliability Engineering
- Forward-Looking Implications for the Tech Industry
Meta has deployed DrP, an innovative automated Root Cause Analysis (RCA) platform, within its extensive digital infrastructure to significantly reduce the Mean Time To Resolve (MTTR) for system incidents and alleviate the substantial burden on its on-call engineering teams. This strategic implementation addresses the escalating complexity of managing interconnected components in large-scale systems, effectively transforming incident investigation from a manual, time-consuming endeavor into an efficient, programmatic process.
The Challenge of Hyperscale Incident Management
The digital landscape is characterized by increasingly intricate systems, where a single service outage can cascade across numerous dependencies, creating a labyrinthine challenge for incident responders. Traditionally, identifying the root cause of such failures has relied heavily on human expertise, manual log analysis, and collaborative troubleshooting—a process often referred to as “on-call toil.” This manual approach contributes directly to elevated MTTR, impacting service availability and user experience across global platforms. For tech giants like Meta, where uptime and performance are paramount, the inefficiencies of conventional incident management present a critical operational bottleneck.
DrP’s Programmatic Automation at Scale
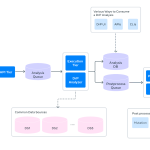
DrP’s core innovation lies in its capacity to programmatically automate the entire incident investigation workflow. By leveraging advanced data correlation and dependency mapping, the platform can swiftly pinpoint the precise origin of a system failure, even within Meta’s sprawling ecosystem of services and microservices. This automation drastically cuts down the diagnostic phase, which often accounts for a significant portion of incident resolution time.
The platform ingests vast quantities of operational data, from system logs to performance metrics, intelligently sifting through noise to identify causal links that human investigators might overlook or take hours to uncover. This intelligent processing ensures that the most relevant information is surfaced rapidly, enabling engineers to focus on remediation rather than prolonged investigation. DrP’s design specifically addresses the challenges of operating at Meta’s immense scale, handling a volume and complexity of data that few other systems can match.
Transformative Impact on MTTR and Engineering Efficiency
The direct impact of DrP is a demonstrated reduction in MTTR, a key performance indicator for operational efficiency and system reliability. By accelerating the identification of root causes, incidents are resolved faster, minimizing downtime and its associated financial and reputational costs. Furthermore, DrP liberates on-call engineers from the arduous, repetitive tasks of initial investigation, allowing them to focus on more complex problem-solving, preventative measures, and system enhancements. This shift not only improves engineer morale but also optimizes resource allocation within Meta’s engineering divisions. The platform’s robustness ensures consistent performance in identifying emergent failure patterns within a continuously evolving infrastructure.
A New Standard for Site Reliability Engineering
While specific data points remain proprietary to Meta, the widespread deployment and reliance on DrP within the company affirm its significant value. Engineers at Meta have consistently highlighted the challenges of managing incidents in a hyper-scale environment, where the sheer volume of telemetry data can overwhelm human analysis. DrP directly addresses this by acting as an intelligent orchestrator of diagnostic information, presenting actionable insights rather than raw data.
Industry trends indicate a growing reliance on AI and automation for operational tasks, with enterprises recognizing the limitations of human capacity in an increasingly automated world. Platforms like DrP represent the vanguard of this shift, demonstrating a practical application of machine intelligence to a pervasive operational challenge. Its success within Meta serves as a potent case study for other large organizations grappling with similar incident management complexities.
Forward-Looking Implications for the Tech Industry
The emergence of platforms like DrP signals a pivotal evolution in site reliability engineering (SRE) and DevOps practices across the industry. It establishes a new benchmark for incident response, moving beyond reactive human intervention towards proactive, automated diagnostics. For businesses, this translates to enhanced service stability, reduced operational overhead, and a competitive edge derived from superior uptime. For the engineering workforce, it implies a fundamental shift in skill requirements, emphasizing architectural understanding and system design rather than purely reactive troubleshooting. The “on-call” role itself may transform, focusing more on system resilience and automation development rather than manual firefighting.
Looking ahead, the success of DrP at Meta will likely accelerate the development and adoption of similar AI-driven RCA tools across the broader tech landscape. Competitors and cloud providers will face pressure to develop comparable capabilities to maintain service reliability and operational efficiency. The potential for open-sourcing components or methodologies from DrP could democratize advanced incident management, making sophisticated automation accessible to a wider array of organizations. Furthermore, the continuous refinement of such platforms will likely lead to even more predictive capabilities, allowing systems to anticipate and mitigate potential failures before they impact users, thereby shifting the paradigm from reactive resolution to proactive prevention. The future of digital infrastructure management is undeniably automated, and Meta’s DrP is a clear indicator of this trajectory.